复制(二)#
本文是(Designing Data-Intensive Applications)第五章的读书笔记的第二部分。我们在复制(一)中介绍了分布式系统下复制的作用,面临的主要问题并重点介绍了Single-leader Replication(单主机复制)。本文会接着介绍Multi-leader replication。而Leaderless replication会下后续的笔记中讨论。
Multi-leader replication#
Multi-leader和Single-leader在很多方面都很相似。整个分布式数据库中,不仅仅只有一个leader,而是存在多个leader。每个leader有自己的follower,当有数据写入/更新时,更新需要复制到它的follower中去。这个部分和Single-leader replication下面的实现基本时一样的。唯一特别指出时,当我们像一个leader节点写入/更新时,这个leader上的改动也需要复制到其他leader节点上。请注意,到其他节点的复制可以时异步的。
Use Case 1: Multi-datacenter operation#
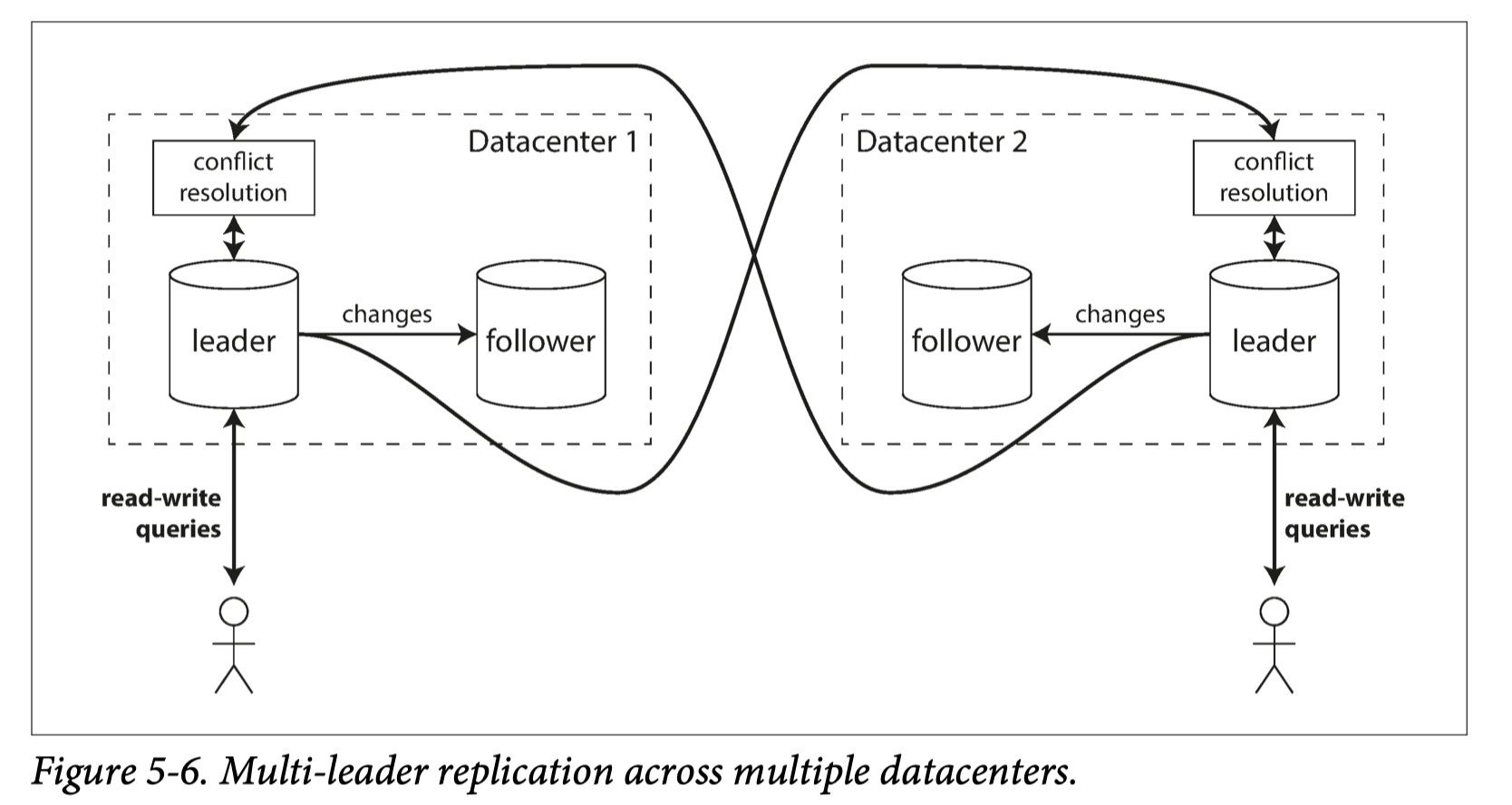
从性能角度比较:#
In a single-leader configuration, every write should go over the internet to the datacenter with the leader. This can add significant latency to writes and might contravene the purpose the having multiple datacenters in the first place. In a multi-leader configuration, every write can be processed in the local datacenter and is replicated asynchronously to the other datacenters. Thus the inter-datacenter network delay is hidden from users, which means the performance may be better.
当我们有多个data-center时,我们希望可以在地理位置上最接近的data center写入和读取数据。可是,如果是Single-leader Replication,势必只会有一个data-center的网络中有leader节点。那意味着,所有的写入操作都需要路由到这个data-center中。对于地理位置很远的客户端,这样的设计显然是非常不便而低效的。
Multi-datacenter 配置Multi-leader replication,比较典型的做法是,一个data-center配置一个leader,data-center网络内部的节点都从属于同内网的leader。当客户端想要写入和读取数据,只需要访问最近的data-center的leader。data-center之间的数据复制可以是异步的。
从容错角度#
Single-leader配置下,leader挂了,failover非常慢。而且数据snapshot需要copy到另一个datacenter中。
Multi-leader配置下,一个data-center的leader挂了,不太影响其他data-center的运转
从网络角度#
Single-leader配置下,inter-datacenter网络质量对非常敏感。
Thus the inter-datacenter network delay is hidden from users, which means the performance may be better.
Use case 2: Clients with offline operation#
简单说,就是有时候分布式系统的一部分可能需要从Major network分离开一阵子。我们希望离线的部分内部还是可以正常读写。直到重新连接回系统,再和系统进行信息/数据的同步交换。
Use case 3: Collaborative editing#
在线协作最好也是用Multi-leader的配置方式。用户编辑的时候,往自己本地的leader写入/更新数据。不同的用户的leader节点之间周期性的进行数据同步和冲突处理
写冲突#
Multi-leader有很多好处,容错性也高。唯一需要解决的问题就是写冲突的问题。想象一下,如果我们只有一个脑子,并且只往这个脑子里面写东西,所有的数据复制也都由这个脑子来指挥。那么,很容易保证系统的最终一致性。这就是Single-leader的配置。
然后Multi-leader的配置下,我们有了多个脑子,不同的人可能往不同的脑子写数据,更糟糕的时候,可能修改了同一个记录。那么,这些脑子(leader)之间就需要处理这些写入,特别是有冲突的写入。
Multi-leader configuration下,同步 vs 异步 conflict detection#
同步比较好理解,就是每一次向一个leader写入数据时,需要等待其他所有节点(其他leader)的写入完成,然后就可以侦测到是否有冲突发生。但这个显然违背了Multi-leader设计的初衷。我们希望每一个leader的写入尽可能独立。如果需要同步等待,还不如直接使用single-leader。
异步场景下,每一个leader都会有数据写入。数据冲突往往需要在异步的数据复制/交换的时候才能侦测到。这个时候,原先的写入已经完成,比较返回给用户了。一般地,我们需要请求用户处理冲突。
下面,我们就来介绍几种冲突解决办法:
1. 避免冲突 Conflict avoidance#
针对特别的场景,配置leader,使得冲突不会发生。举例来说,同一个user只会在一个data-center写入和修改数据。那么,就不存在来自其他data-center的对同一块记录的冲突编辑了。
2. Converging toward a consistent state#
Single-leader的场景下,写入冲突可以按写入顺序来解决。后来的写入会覆盖先前的写入。
Multi-leader下,很难决定写入顺序。
- Unique ID (时间戳,UUID)来排序
- merge value
- Record the conflict in an explicit data structure.把冲突暴露给用户, 让用户来处理冲突
Multi-Leader Replication 拓扑#
- Circular
- Star
- All-to-all