Replication复制(一)#
Why: 为什么我们需要复制#
What: 先说定义,什么是复制:
Replication means keeping a copy of the same data on multiple machines that are connected via a network.
用我的话说就是,在一个分布式集群里,为一份数据,维护多分副本,存在多台设备上。
Why: 为什么我们需要复制?
对于分布式系统来说,可以说,几乎所有的设计都绕不开,可用性,可靠性,可扩展性,容错这几个目标。复制也不例外。
- 高可用性(high availability): 集群里,一台或者某几台机器挂了,系统还可以继续运行(因为有relica,数据没有丢)
- 降低延迟:数据可以复制并分布在不同的区域,地理上尽可能靠近用户。(geographically close to users)
- 可扩展性: reads on replicas 可以提供读吞吐。(如何考虑复制引入写性能的瓶颈问题?)
请注意,这一章节简化了复制的讨论场景,假设复制的数据都是一台机器足够装下的。(如果装不下怎么办?化整为零,分散存放。Sharding/Partitioning。因为Partition的引入会让复制的讨论更复杂,所以本章所讨论的复制数据集都是一个机器就可以完整存放的)
Chanllege: 复制引入的问题:
- 一致性
- 容错(故障恢复和错误处理)
How: 如何复制#
如何复制看似很简单的问题,复制不就是构造一摸一样的数据内容吗?
复制看似简单,实际上,里头很多需要考虑的问题。例如,原始的数据(主本)在哪里?副本存放在哪里?一种显而易见的方式就是先把数据写到一个节点上,其他的备份节点(relica)都从这个节点复制数据。这个写入数据的节点,我们叫leader,备份的节点,我们叫follower。
Leader/Follow#
按Leader/Follow的结构,复制可以分为:
- Single-leader replication
- Multi-leader replication
- Leaderless replication
Leader: 就是跟用户对接完成写操作的那个节点。从用户视角来说,Leader 确认写成功了(commit write),用户就认为写完成了。
Follower: followers负责保持和leader相同的数据副本。值得注意的是,follower对用户写是不可见的。用户写操作完成了,follower上可以还没有完成副本的写入。
同步和异步复制#
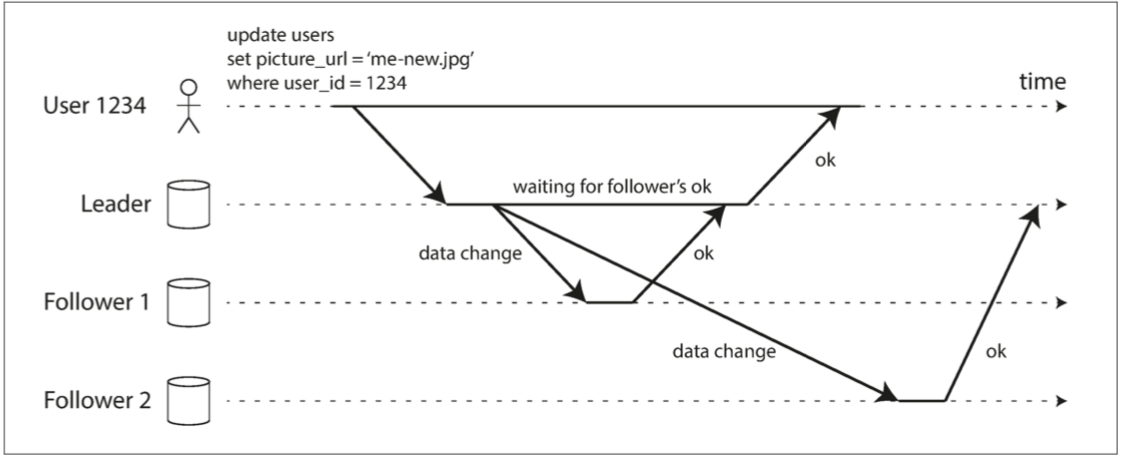
在leader-based的复制机制下,用户写入复制的基本步骤就是:
首先,用户往leader发写请求并传输写数据
然后,leader写入数据。同时leader像其他的follower节点发出复制的请求。
最后,leader回复用户写操作已完成。那么,问题来了。leader回复的呢?是等所有的follower回复确认之后,还是不等follower回复就直接响应用户呢?这就涉及到复制的同步和异步机制。
- 同步地复制:Leader发起复制请求后,需阻塞等待直到收到follower确认回复后。图例中的Leader对Follower1就是同步复制。
- 异步地复制:Leader发起复制请求后,不需要等待follower的回复。图例中的Leader对Follower2就是异步复制。
- 半同步复制(semi-synchronous): Leader发起复制请求后,只需要等待一个Follower reponse。图例其实就是一个半同步的复制。
| 优点 | 缺点 | |
|---|---|---|
| 同步复制 | 一致性。保证follower和leader的数据始终一致 | 慢。更糟的是,一个follower复制的慢,或者没响应,会影响整体的写操作。 |
| 异步复制 | 快 | 复制延迟。Leader/Followers数据不保证一致性。Follower的数据往往落后于Leader的数据。a write is not guaranteed to be durable, even if it has been confirmed to the client. |
弱一致性听起来似乎很扯,但事实上,异步复制广泛地被使用。我们要解决的复制延迟带来的问题。
复制过程中的新增节点和节点失效的处理机制#
处理新增一个Follower#
Leader和Followers都是生活在集群里,我们难免遇到需要增加或者减少一个节点的情况。
场景1:为了提高系统的可靠性,有时候可能需要增加副本数,这时就需要新增follower。
场景2:旧的follower机器可能老化了,或者故障了,需要更换新的follower。
无论何种场景,当我们需要新增一个follower的时候,需要解决就是如果使leader和新follower的数据一致。
- 天真的办法:从leader上面一块一块的搬砖到follower上。这个方法显然不可取。需要锁住leader的数据,然后copy数据。整个系统会halt住
- 一般的做法:snapshot + log
- leader database定期保存snapshot
- copy snapshot to new follower. (background processs)
- Follower 连线leader,并请求snapshot 之后的replication log日志
- Follower用获得的replication log更新数据,直到追上leader的日志caught up。
遗留的问题:
- 对snapshot的理解还有点模糊。snapshot对节点的性能的影响。
- follower获取从上一个snapshot到up-to-date之间的data change log,然后catch up这一部分的数据。与此同时,leader也在不断写入新数据。这个过程中额外增加的data change怎么追上呢?
处理节点失效: Handing Node Outages#
Follower fail#
follower保持a logs of the data changes. Crashes之后恢复之需要跟leader同步从崩溃前的transations开始catch up后面的data changes就可以。
Leader fail#
Leader fail相对麻烦一些。
- detect leader fail。使用timeout (heartbeat?)
- 选新leader. (through an election process: raft, paxos ?)
- 重新配置新leader. 客户端需要知道新leader(Page 214 Request Routing)
引入的问题:
- 如果系统使用的是异步的复制策略,新leader很可能没有同步到老leader的所有数据。新leader miss的那些写操作怎么处理?老leader 重新回到集群中,怎么解决写冲突?一般地做法就是,一切以新leader为准,miss掉的那些write操作直接忽略掉。当然,这就违背了客户的预期,undurability
- 如果集群还需要与外库同步数据,选举新leader,直接丢弃miss掉的写操作可能会带来严重的后果。
- Split brain的问题。有一些系统提供leader detect机制,发现多leaders的时候,会shutdown一个。
- Leader的fail detect timeout 怎么设置合理?
更多深入的讨论会在第八章,第九章。
复制日志的实现:Replication Logs#
- Statement logs
- statement的执行可能是非确定性的。
Now(), Rand()函数每一次执行结果可能都不同。这样就无法保证其他follower上执行statement之后的结果(状态)和leader一致 - 有的语句的执行结果和执行顺序大有关系。比如包含autoincrease column的INSERT ROW等
- 有的语句有副作用。
- statement的执行可能是非确定性的。
- Write-ahead log(WAL) shipping
- append every disk write to a log.
- 这个策略的问题就是太低层了。详细到往disk的那个位置修改那个byte。和存储介质、存储格式都有紧密联系。
- Logical (row-based) log replication。逻辑的日志复制
- log的内容和底层存储以及编码解耦。
- Trigger-based replication
- 暂时先不深入。
复制延迟带来的问题#
什么是复制延迟?
上文讨论复制的同步、异步的时候,其实已经碰触到这个概念了。复制延迟,就是指,在异步复制的分布式系统里,Follower节点的数据往往会比Leader节点要落后一段时间。这段时间就是复制延迟时间replication lag。当然,只要系统是健康运转的,最终follower节点也会慢慢追上这些数据。我们称为主从数据具有最终一致性
要知道leader-based的架构里,客户端从leader写,但是有可能从follower读。如果刚好所读的follower节点落后太多,那么就有可能读到过时的数据。这有时候会带来非常糟糕的体验。
场景1: 用户想要浏览自己刚刚修改的信息,却发现还是修改前的数据。Reading your own writes。
解法1: 浏览只有用户自己会修改的信息时,总是去leader读。比如用户自己的个人信息只有自己可以修改。永远去leader读取个人信息。这种方案很有局限性。很多信息都是会被很多其他用户修改的。
解法2: 跟踪Leader和Follower的上一次更新信息的时间。如果读取刚更新的信息(比如,1分钟以内修改的),就从leader读。如果读取更久远一点的信息,就从follower读。
解法3:在客户端上面根据客户端的上一次更新时间。然后和follower的最近一次更新时间比对。如果从库更老,就从其他从库读,或者从Leader读。
这种方案的局限性就是需要维护到客户端的更新时间。并且,如果有多个客户端,跨平台的场景,跟踪用户的信息更新行为代价就要更大。
2.還有麻煩的一點 如果你的所有副本存儲在不同的datacenter 那很難保證不同的設備連到同一個數據中心(電腦連的有線網路跟手機連的無線網路連到的數據中心可能不同) 如果你想要讀同ㄧ主庫 你也需要有個中心存儲來保證同一個用戶永遠讀到同一個數據中心
场景2: 用户看到时光倒流。用户先后两次发起同样的查询。由于前面一次访问了一个update-to-date的follower,既而浏览最新的信息。第二次因为访问到一个很老的follower,看到的数据反而是老数据。既而有一种时光倒流感。
為了避免這種情況 我們需要單調讀(Monotonic reads)的機制。這個保證比強一致性弱 但比最終一致性強
解法1: 同一个用户的查询都指向同一个节点。但是,如果这个节点fail了,用户还是需要rerouted到一个其他节点。需要想办法保证不会路由到一个更老的节点。
场景3: 一致前綴讀 Consistent Prefix Read。在很多场景下,数据前后有因果逻辑关系,这时,要求用户读出来的顺序应该同写入的顺序一致。可以慢,但顺序不可以错乱。
實作方式是 確保任何因果相關的寫入都寫入相同的分區
参考文献#
1. Designing Data-Intensive Applications
3. Designing Data-Intensive Applications 心得筆記,jyt0532’s Blog