Catalog#
Reference#
Spark: Cluster Computing with Working Sets, Matei Zaharia, 2011
Introduction#
RDD is the most important concept of Sparl. It make it possible to access one DataSet
The main abstraction in Spark is that of a resilient distributed dataset (RDD), which represents a read-only collection of objects partitioned across a set of machines that can be rebuilt if a partition is lost.
RDD can be cached in memory.
Users can explicitly cache an RDD in memory across machines and reuse it in multiple MapReduce-like parallel operations.
- a general shared memory abstraction
- represent a sweet-spot between expressivity
- scalability
- reliability
We believe that Spark is the first system to allow an efficient, general-purpose programming language to be used interactively to process large datasets on a cluster.
Programming Model#
a driver program#
resilient distributed datasets
parallel operations
Resilient Distributed Datasets (RDDs)#
A resilient distributed dataset (RDD) is a read-only collection of objects partitioned across a set of machines that can be rebuilt if a partition is lost.
- read-only collection
- accross a set of machines
- can be rebuillt
A handle to an RDD contains enough information to compute the RDD starting from data in reliable storage.
Spark lets programmers construct RDDs in four ways:
From a file in shared file system
By “parallelizing”
By transforming an existing RDD
By changing the persistence of an existing RDD
The cache action
cache action is only a hint, if there is not enough memory in the cluster to cache all partitions of a dataset, Spark will recompute them when they are used.
The save action evaluates the dataset and writes it to a distributed filesystem such as HDFS.
Q: what is the different between “parallelizing” and “transforming”
We also plan to extend Spark to support other levels of persistence (e.g., in-memory replication across multiple nodes). Our goal is to let users trade off between the cost of storing an RDD, the speed of accessing it, the proba- bility of losing part of it, and the cost of recomputing it.
Spark plan to support in-memory replication.
Let users trade off between storage, speed, data-lost and re-compute cost.
Parallel Operations#
- reduce: Produce a result at the driver program.
- collect: Sends all elements of the dataset to the driver program
- foreach: Passes each element through a user provided function
- to be supported:
- shuffle
#
- Broadcast variables
- If a large read-only piece of data
- Accumulators
- workers can only “add”
- only the driver can read
Exampels#
Text Search#
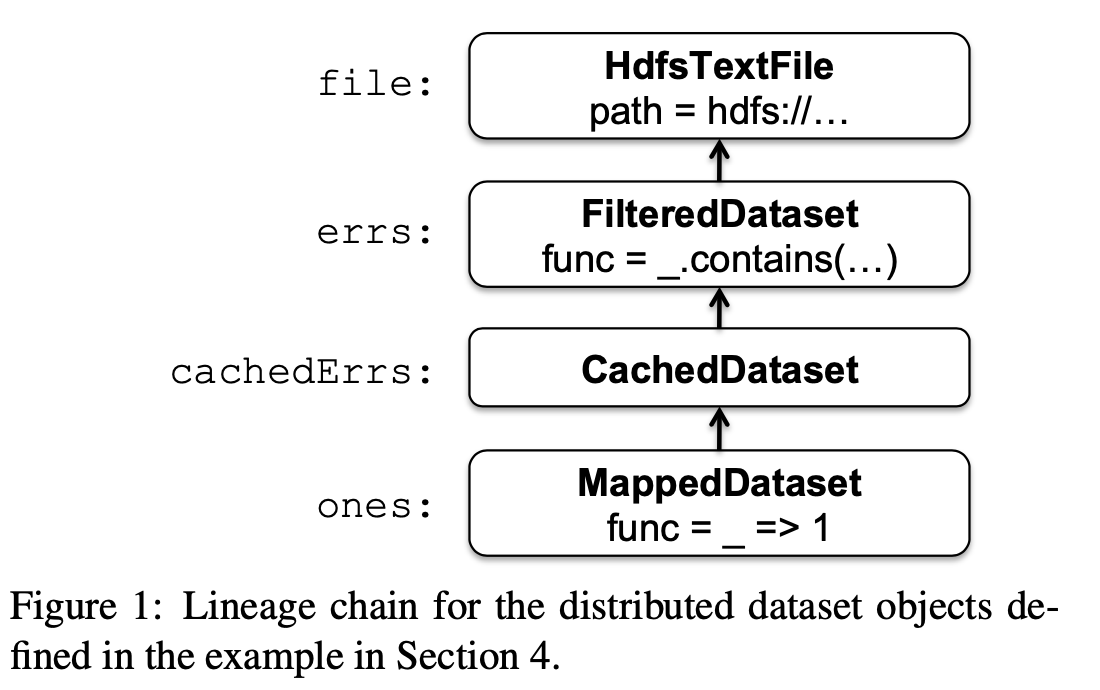
Suppose that we wish to count the lines containing errors in a large log file stored in HDFS.
- firstly, create a distribute dataset
- secondly, transform it by operate
filterop - then we use
mapandreduceoperations to count the dataset
Implementation#
Spark is built on top of Mesos provides an API for applications to launch tasks on a cluster.
The core of Spark is the implementation of resilient dis- tributed datasets.
Internally, each RDD object implements the same simple interface, which consists of three operations:
- getPartitions, which returns a list of partition IDs.
- getIterator(partition), which iterates over a partition.
- getPreferredLocations(partition), which is used for task scheduling to achieve data locality.
The different types of RDDs differ only in how they implement the RDD interface.
Shared Variables
The two types of shared variables in Spark, broadcast variables and accumulators, are implemented using classes with custom serialization formats.
using classes with custom serialization formats
#
- Distributed Shared Memory
- Cluster Computing Frameworks
Future Work#
Furthermore, we believe that the core idea behind RDDs, of a dataset handle that has enough information to (re)construct the dataset from data available in reliable storage, may prove useful in develop-ing other abstractions for programming clusters.
- Formally characterize the properties of RDDs and Spark’s other abstractions
- Enhance the RDD abstraction to allow programmers to trade between storage cost and re-construction cost.
- Define new operations
shuffle - Provide higher-level interactive interfaces
My Future Work#
RDD is core of Spark
Do more research on Spark’s task schedule
HybridSEmay also use similar concept of Distribute Datasets or directly use Spark’s RDD. Then we have to:- Make sure fedb implement HybridDD correctly
- Try to adapt Spark RDD to HybridDD